Building Image search with OpenAI Clip
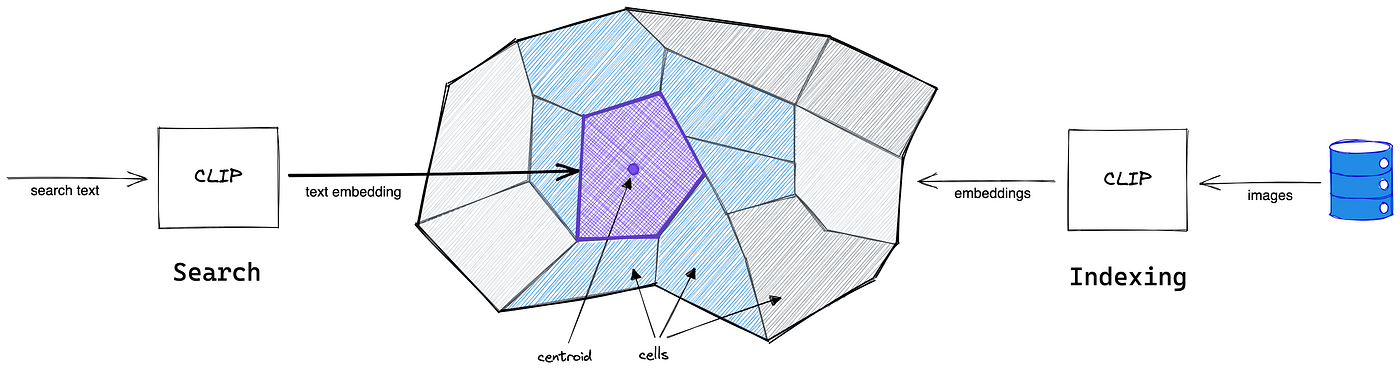
OpenAI’s Clip is a neural network that was trained on a huge number of image and text pairs and has therefore learned the “connection” between them. This means it can embed the text and images into joint semantic space which allows us to use it for the most similar image for a given text or image.
Let’s try to build our own (small scale) Google Image Search! For that, we need to:
- Convert the images into embeddings (=vectors) with Clip
- Index the image vectors with Faiss
- Build the image search using the data from the previous steps
Image embeddings
First, we need to run images through the Clip model to create embeddings for them. This will allow us to look up the image with the most similar embedding (vector) for the given search query.
I’m using the sentence-transformers library to load the pretrained Clip model. The library provides a simple interface for loading and interacting with the model so converting the images into embeddings is quite straightforward.
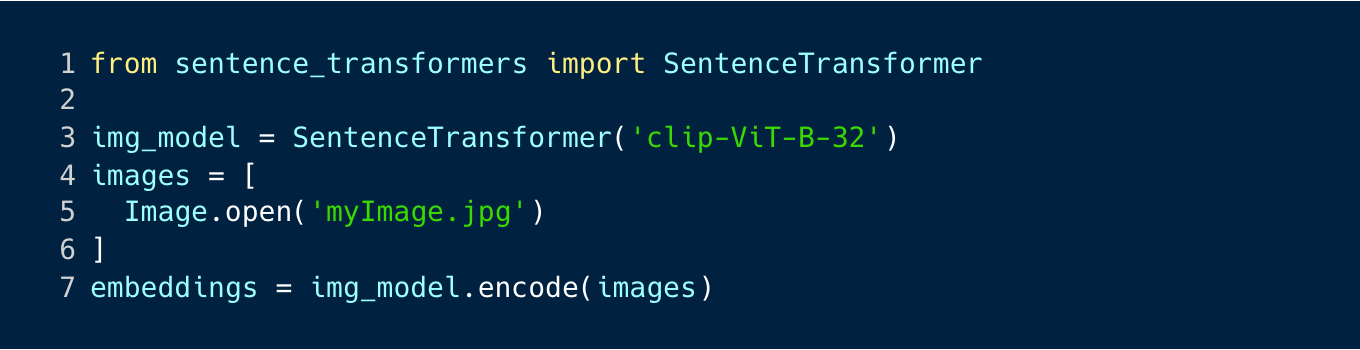
Encoding a single image takes ~20 ms with a single Nvidia V100 GPU and 1 million images takes ~90 minutes. With a large number of images, it’s good to encode the images in larger batches to minimize the overhead of sending the data to the GPU.
Index for the image vectors
To efficiently look up the most similar images for a given text query, we need to index them. There are many solutions available for doing this, including some PaaS solutions, like Vertex AI Matching Engine, but I decided to go with Faiss. Faiss is a library from Facebook for efficient similarity search and clustering of dense vectors. It offers many different functionalities, such as:
- Basic vector similarity search without any clustering or compression
- Partitioned index with Voronoi cells to do an approximate search (to speed up the search)
- Vector compression using product quantization (to reduce the memory footprint)
Building the index
I chose the IndexIVFFlat index type, which creates a partitioned index to allow faster lookup. The vectors are grouped into clusters (Voronoi cells) and the search checks the vectors from the best cluster(s). Which allows faster searches but might not always return the most accurate results. You can balance between speed and accuracy by choosing the number of clusters but also how many clusters to visit when searching.

“Flat” part of the name tells that the vectors are stored as is, without any compression or quantization. You could also do product quantization which compresses the vectors in the index. This reduces the memory footprint but also approximates the vector similarity calculation and therefore reduces the accuracy as well. Faiss has really good documentation on their Github page about the different indexes & compression techniques: https://github.com/facebookresearch/faiss/wiki/Faiss-indexes

The index_factory function allows building those composite indexes easily since we need an index to find the best cluster and then another index for the vectors in the cluster.
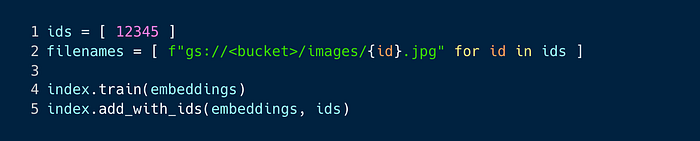
The training just finds the most optimal cluster centroids so you don’t necessarily need to train it with all the indexes. I’m also adding the vectors to the index with IDs so it will be easier to look up the actual image files. The ID is just a unique random number which will be also used as the filename of the image on GCS.
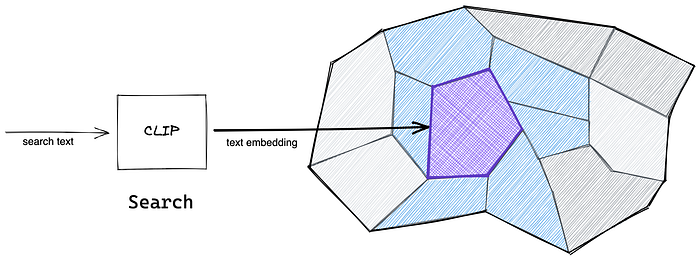
The image search
Finding for the most similar images for the given text is just a vector similarity search:
- Convert the text into a query vector
- Find the most similar vectors from the index for the query vector
- Lookup the image files from GCS using the (image) vector ID
The multi-lingual version of the OpenAI CLIP-ViT-B32 model (clip-ViT-B-32-multilingual-v1) from the sentence-transformers library, can be used to convert the search query into a vector. This allows us to map text in any language to the same semantic space with the images. I.e. a text “red car” or “carro rojo” will get a similar vector as an image of a red car.


You can see the power of Clip by changing the “men” to “women” in the previous search query. Clip can distinguish women from men (in the traditional 2-gender world) and therefore you will see photos of women playing soccer instead. Of course, Clip doesn’t really understand genders but it has just learned that these types of images appear together with the word “women”.

As said, since this is just a vector similarity search, you can use any vector for searching, including a vector made from an image:
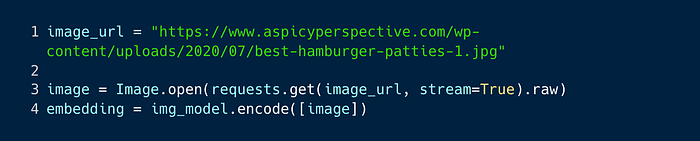
The above code looks for the most similar images to a photo of a hamburger, which are (surprise, surprise) also about hamburgers.

Nice! As you can see, you can quite easily build your own image search and start competing with Google! Well, you might need a few additional images in your index and a distributed index.
With Clip and all language models, it’s good to remember that they have various biases. Or rather, they have learned them from the content they have been trained on. For example, they might associate doctors with men and housekeepers with women. Or if certain groups of people commit more crimes than others, you might get images of these groups as results when searching for crime photos. Here’s one related study of biases in OpenAI’s Clip: https://venturebeat.com/2021/08/10/audit-finds-gender-and-age-bias-in-openais-clip-model/
