Time series forecasting for Prometheus & Grafana with BigQuery ML
Use BigQuery ML for adding forecasting capabilities to Prometheus and make your monitoring smarter

For monitoring & alerting, I’m using Prometheus and Grafana, which are great tools for this. But some of the metrics have trends and recurring patterns which makes it hard to monitor them with threshold-based alerting. So I wanted to see if BigQuery ML can come to rescue. It offers time series forecasting which is perfect for spotting changes in the usual patterns of your data.
I didn’t want to build an external monitoring system, so the goal was to create a Prometheus exporter which provides predictions for your Prometheus metrics using BigQuery ML.
The steps for implementing this are:
- Loading historical data from Prometheus (for specific metrics)
- Training time series forecasting model with BigQuery ML
- Forecasting future values and exposing them to Prometheus
- Visualizing the forecasted values with Grafana
Let’s see next what was done in each step but first, a few words about ARIMA and BigQuery ML.
ARIMA PLUS in BigQuery ML
ARIMA, which stands for Auto Regressive Integrated Moving Average, is one the most popular statistical methods for time series forecasting. It’s a class of models that “calculates” one observation based on the previous (lagged) observations. Many good articles are describing in detail how ARIMA works so don’t try to replicate them here. If you’re interested to learn more, look at this, for example: https://otexts.com/fpp2/arima.html
BigQuery ML’s ARIMA PLUS also includes many additional features, such as anomaly detection, holiday effect modeling, seasonality detection and trend modeling. But (as always with BigQuery), you also need to be careful with the costs if you have a lot of data. BigQuery can process massive amounts of data in a blink of an eye, so you can easily spend a lot of money quickly as well. For time series models, BigQuery ML also fits multiple candidate models which increases the costs as well. The AUTO_ARIMA_MAX_ORDER training option can be also used to balance between the accuracy and speed/cost.
Loading historical data from Prometheus
I wanted to make this easily configurable so the application accepts a YAML file containing the metrics you want to forecast for and how often you want to retrain the model.
The following code loads the necessary data from Prometheus API and converts the values to a list of date-value pairs for further use.
Training time series forecasting model with BigQuery ML
For training the model with BigQuery ML, the data needs to be in BigQuery as well. I decided to create a separate table with short expiration time for each configured metric since the data is only needed for short while when training the model.
The timestamp column contains the time for the metric which is required for training the model, while the insertTimestamp is the time when the data was inserted to the table. This allows to drop the old training data from the table soon after the model is trained.
Since the Prometheus query can return multiple time series, I’m storing the name of each time series to train a different model for each of them.
Training the model with BigQuery ML is super simple. You only need to give the following parameters:
- time_series_timestamp_col: Name of the timestamp column
- time_series_data_col: Name of the value column
- time_series_id_col: Name of the ID column. This allows to train multiple time-series models with a single query.
- auto_arima: Enables auto.ARIMA which tries to find the best possible hyperparameters for the model.
There is a bunch of additional parameters you can set as well, but the default values are often good enough.
The training time depends on the amount of data you have, but with 30 days’ worth of data with 5 min granularity, the training takes only a few minutes.
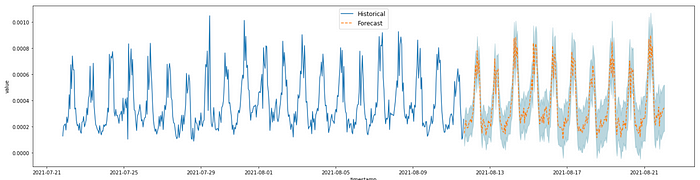
Even though the plan is to push the predictions back to Prometheus, I’m also using a Colab notebook for visualizing the predictions. This enables me to see how the model works immediately after training since you cannot push future data points to Prometheus.
Big thanks to Lak Lakshmanan for providing a sample notebook for this!
You can also view the trained model from BigQuery UI:

Predicting future values and exposing them back to Prometheus
Since I didn’t want to introduce any new tools, I’m pushing the predictions back to Prometheus which allows to visualize them with Grafana and create alerts based on them using Prometheus’ Alertmanager.
The application calls BigQuery periodically to get the forecasts and then exposes an endpoint for Prometheus to scan them. Since the forecasts won’t change unless you retrain the model, you can forecast multiple time points at once and then expose them to Prometheus when the (future) time comes.
I’m using Spring Boot so a natural choice for exposing these to Prometheus is to use the Micrometer library. It’s nicely integrated with Spring Boot Actuator which provides /actuator/prometheus endpoint to Prometheus for loading the metrics.
The application creates gauges for the forecasted values and for the prediction interval, given the confidence level I used. It also exposes out-of-bounds counter which helps to builds alerts on how often the actual value doesn’t fall into the prediction interval.
The labels for Prometheus (or Tags in Micrometer’s vocabulary ) are the same as in the original PromQL query. This allows you to group the forecasted values the same way than for the original metric. E.g. if you’re forecasting for sum(rate(my_metric[15m])) by (label1, label2), the forecasted values can be queried with avg_over_time(my_metric_forecast_value[15m]) by (label1, label2)
Visualizing the forecasted values with Grafana
I’m using Grafana for visualization so I wanted to show the forecasts there as well the same way as in the Colab notebook shown earlier. Since the application exposes the upper and lower bounds for the predictions, you can visualize the prediction interval with a little bit of Grafana magic.
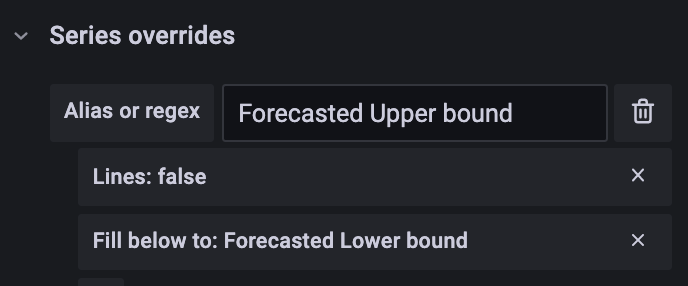
Grafana has “Fill below to” style override where you can customize how it fills the series. As seen the image on the left, I’m telling it to fill the Forecasted Upper bound down to the Forecast Lower bound, so it paints the prediction interval.
When you combine this with your original metric, it nicely visualizes how the actual values follow the predicted values (or not):

There you go! BigQuery ML is a great option for adding ML capabilities to your applications since it’s relatively easy to implement, inexpensive (with some exceptions) and a truly scalable solution.
Let me know what do you think about this! All feedback is welcome!
